Software rot
The software development life cycle is predictable in that any long-lived product will eventually outgrow some of its subsystems. For instance a Web service that begins life with a single monolithic database server will as it scales need the capacity increase that comes from a distributed database. A historical example can be found in Twitter’s original dependence on the ActiveRecord ORM, which over time was replaced with a variety of databases and services.
For historical reasons
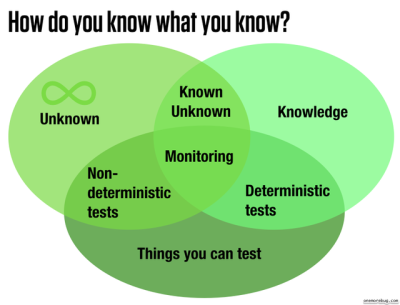
In one sense this might be considered as a canonical definition of legacy systems: the system contains subsystems that are not optimally suited to day-to-day functioning despite the fact that at some point in the past those same subsystems did function optimally. There is a concept of Software Rot or Bit Rot that metaphorically encapsulates the life cycle phases that precede this sort of legacy system.
Frictionless yet it still wears out
The observed course of the software development life cycle is that features begin life in a “working” state — meaning that they satisfy the requirements agreed upon by an empowered group of stakeholders — but that inevitably the same features begin to exhibit bugs that are not in any way related to changes of code nor hosting environment. Software rot (as this phenomenon has come to be called) is caused because the requirements for features continue to change and evolve even after such features are in the hands of their users.
the system contains subsystems that are not optimally suited to day-to-day functioning
This is not a well-understood area of software production, nor does Computer Science have much to contribute by way of solutions. The problems are not algorithmic but environmental, social, aesthetic — in other words it is what programmers like to call a squishy problem because so much of the problem space is taken up not by software but by humans and their co-collaborators.
In programming, soft skill is hard
The idea of engaging with squishy problems is uncomfortable to a lot of programmers. I think this is because programmers currently do not have an opportunity to learn the heuristics that would allow them to distinguish good solutions from bad when it comes to human-and-social issues.
Taking software rot as an example, it is a well-known phenomenon long documented in the literature of software. Yet it has no commonly-agreed up on solution. Its management is not a topic of discussion in job interviews nor in performance evaluations (for the most part). The contraventions for software rot are not listed in general programming books nor taught in coding boot camps.
I do not believe that software rot is ignored as a topic because no one recognizes its importance. I’m pretty sure it’s ignored because no one feels comfortable giving advice about it, because almost no one has successfully dealt with the long-term requirements-changes and subsystem upgrades that go with solving software rot.
The knowledge about how this problem have been successfully dealt with are locked away in a couple of books. And those books are old, using server-side programming and Java as their example environment. That’s a hard sell to a junior engineer fresh out of a boot camp or undergrad program.
The recent movement toward systems thinking in software is a hopeful sign. But we need modern discourse that concerns how to deal with changing requirements over time. And so far such discourse hasn’t been forthcoming despite all the growth and hype about code over the last ten years.